Introduction
Open-source base LLMs, like Facebook’s LLaMA or Microsoft’s Phi models, provide an excellent starting point for natural language processing tasks. Typically, however, these models aren’t well-suited for domain-specific tasks; developers must fine-tune a subset of the model’s weights to improve performance.
The leading approach for memory-efficient fine-tuning involves Low-Rank Adapters (LoRA). LoRA applies a small number of trainable parameters–usually far fewer than the billions of parameters in the LLM–to update the LLM’s self-attention heads. The remainder of the model’s weights are frozen (i.e., not subject to updates).
According to the 2021 Microsoft Research paper outlining LoRA, the authors managed to reduce the GPU memory consumption of fine-tuning GPT-3 from 1.2TB to 350GB (5).

LoRA represents weight matrix 
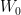


QLoRA (Dettmers et al.) further improves the efficiency of LoRA with quantization. QLoRA recognizes that the largest share of fine-tuning memory consumption is accounted for by the training gradients of the LoRA parameters, rather than the parameters themselves. Thus, QLoRA stores parameters using a 4-bit datatype, and dequantizes them to a 16-bit datatype when they’re needed for computation.
Training Procedure
For my first fine-tuning project, I decided to install the newly-released Windows AI Studio Visual Studio Code extension and fine-tune Microsoft’s Phi-2 base model for sentiment analysis using the sample dataset. Internally, Windows AI Studio uses Microsoft Olive, an optimization framework targeting myriad devices.
Windows AI Studio runs on my local host, as I have a low-tier NVIDIA GPU, but I needed more VRAM to fine-tune in a reasonable amount of time. Luckily, Microsoft Azure offers cost-effective GPU VM instances. I provisioned an NC4as T4 v3 instance with spot pricing. Spot pricing allows Azure to evict (deallocate or delete) the VM when standard VMs need the capacity or the VM price exceeds the configured limit. I configured the VM to deallocate when the hourly price exceeded $0.10.
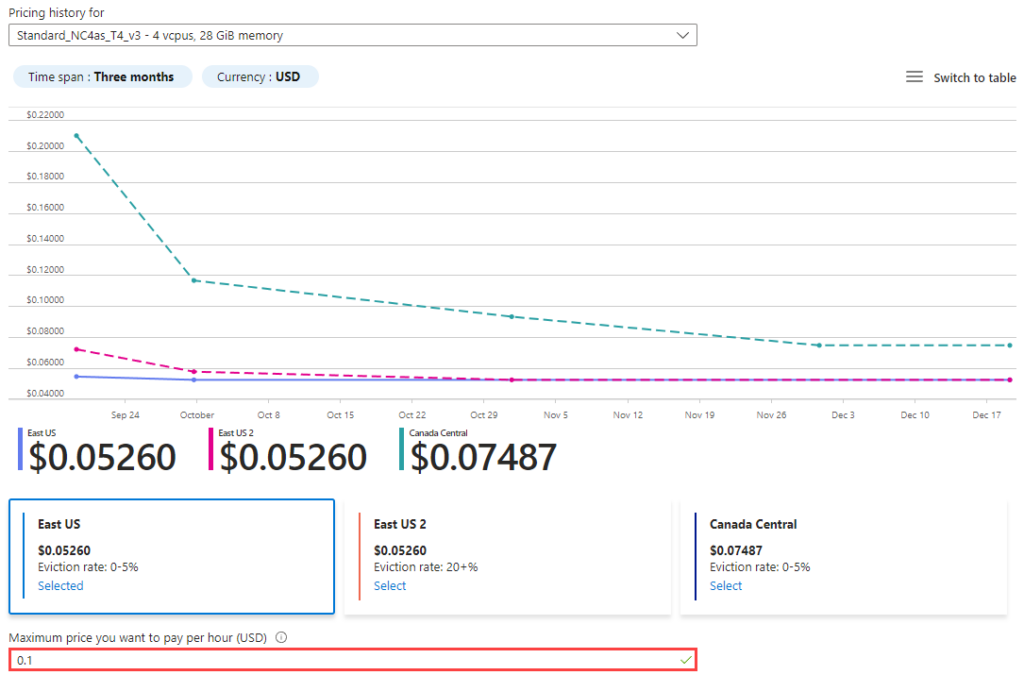
I used Azure’s Data Science Virtual Machine image, which configures Ubuntu 20.04 with common development tools and GPU drivers.
After provisioning the Data Science Virtual Machine, I logged in via SSH. It seemed, however, than the NVIDIA GPU drivers didn’t install correctly. Installing them manually was simple.
sudo apt update
sudo apt upgrade
sudo ubuntu-drivers install nvidia:535-server
To move the files from my local host to the VM, I used WinSCP. After the files transferred, I activated the Conda environment and ran the training script. To my surprise, I received an OOM error. Olive was failing during the backward pass.
My first thought was enabling gradient checkpointing, as we know that gradients consume the largest share of VRAM when applying QLoRA. Checkpointing strategically recomputes gradients for certain nodes, rather than storing them. Unfortunately, Phi-2 doesn’t support checkpointing yet.
My next insight was reducing the rank, from 64 to 4. There’s not much consensus about choosing an effective QLoRA rank. As Dettmers et al. explain, reducing the QLoRA rank only slightly reduces memory consumption (4), but the decrease was sufficient to fit the model on my GPU.
I used the following hyperparameters, yielding loss curves that indicate learning.
| Parameter | Value |
| r | 4 |
| α | 64 |
| LoRA Dropout | 0.1 |
| Gradient Accumulation Steps | 4 |
| Training Steps (Gradient Updates) | 100 |
Wikipedia Comments Dataset
Preliminary Approach
For my next experiment, I decided to fine-tune Phi-1.5 (which only has 1.3B parameters) to classify Wikipedia comments into one or more of six categories of toxicity and hate (it’s also possible for a comment to be benign). I used the dataset from the Toxic Comment Classification Challenge on Kaggle.
To start, I used a Python script (see Appendix) to convert train.csv to a JSONL representation. The dataset indicates categories using one-hot encoding; I converted the categories to a comma-separated list. Interestingly, I found that the model trained better when I added a space between items in the categories list.
{"text": "[SOME COMMENT]", "classifications": "toxic, obscene, insult"}I used N/A to indicate benign comments.
{"text": "[SOME COMMENT]", "classifications": "N/A"}The vast majority of the comments in the dataset of ~140K samples are benign. I chose 16K of the malicious comments (all of the malicious comments in the dataset, except those that could not be decoded as Unicode or exceeded 1,024 tokens) and 15K of the benign comments. I noticed that most of the malicious comments (15K) were flagged as toxic; thus, I included 15K benign comments so that the model wouldn’t learn to always choose toxic and would instead learn how to distinguish between malicious and benign comments. One critical constraint on performance is the underrepresentation of threat and identity_hate in the training dataset; from my rough testing after training, I noticed that the model struggled to identify these categories, even if it flagged other categories correctly.
| Class | # Samples |
| N/A (Benign) | 15000 |
| Toxic | 15092 |
| Severe Toxic | 1505 |
| Obscene | 8314 |
| Insult | 7753 |
| Identity Hate | 1377 |
| Threat | 467 |
To facilitate training, I developed the following prompt template. Fine-tuning prompts should not include instructions, unlike other LLM patterns, such as in-context learning.
### Wikipedia comment: {text}\n### Classifications:\n{classifications}I used the following training parameters, based on multiple experiments tweaking one parameter at a time. I decided to set 

| Parameter | Value |
| r | 8 |
| α | 16 |
| LoRA Dropout | 0.1 |
| Gradient Accumulation Steps | 8 |
| Training Steps | 1000 |
| Gradient Checkpointing | Enabled |
After roughly 200 training steps, there is no clear trend in the train loss. I observed this with learning rates of 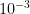
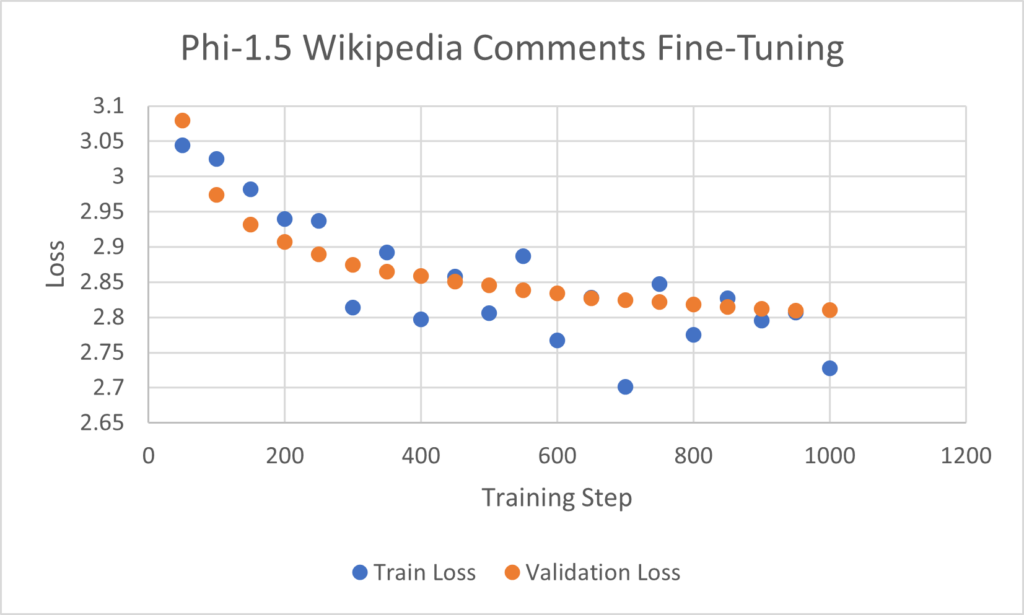
Evaluation
Windows AI Studio conveniently generates starter code using the HuggingFace transformers and peft libraries to perform inference on the fine-tuned model. On the surface, our model seems to perform acceptably, constraining its output to N/A or the six categories of toxicity and hate.
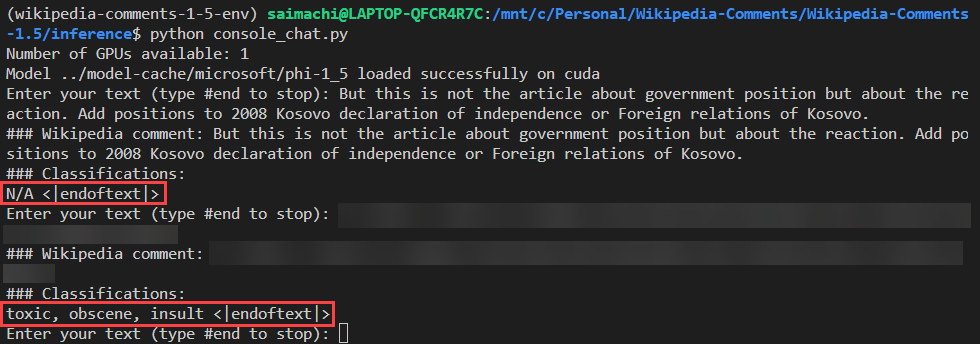
Such rudimentary evaluation is far from sufficient to determine whether the model is production-ready. We know that benign comments comprise roughly half of the dataset. Additionally, toxic, obscene, and insult are the three most common classes of malicious comments in the training dataset. Naturally, the model performs well on these examples. How do we handle cases when the model identifies some, but not all of the classes for a particular comment? Should we weight all misclassification errors the same? Precisely quantifying fine-tuned model performance will be the subject of my next post.