Inspiration
Working in the cybersecurity field, I build alert pipelines that categorize threats based on predefined conditions. For example, was a certain IoC observed? Were any CrowdStrike policies activated? Neural networks can help us build better threat detection models by weighting model inputs (e.g., a binary variable indicating the presence of an IoC) through a learning process.
The Model
I based my neural network on the “Windows Malwares” dataset available on Kaggle. This repository describes various characteristics of a set of executables flagged as benign or one of six possible attacks. I chose to use the DLLs_Imported.csv file, which enumerates the shared object libraries that each executable links to, for a multi-class classification model.
Notable Features
- The first layer is an embedding layer. Embedding layers associate the index of an embedding (a specific DLL) with a vector (in this case, of length 3). Embeddings are typically used in NLP applications to encode semantic information about words.
- The model excludes the final softmax layer; PyTorch’s
CrossEntropyLoss()operates on logits. - The model uses an 80%/10%/10% train/validation/test set. The dataset is shuffled before training.
import pandas as pd
from torch.utils.data import random_split
import torch.nn as nn
import torch
import torch.nn.functional as F
from torch.optim import Adam
import numpy as np
TRAIN_SPLIT = 0.8
VAL_SPLIT = 0.1
TEST_SPLIT = 0.1
EPOCHS = 30
BATCH_SIZE = 64
dlls = pd.read_csv('data/DLLs_Imported.csv')
# Shuffle dataset
dlls = dlls.sample(frac=1)
train, val, test = random_split(dlls, [TRAIN_SPLIT, VAL_SPLIT, TEST_SPLIT])
Xtrain = dlls.iloc[train.indices, 2:]
Ytrain = dlls.iloc[train.indices, 1]
print(f'Train Set Features: {Xtrain.shape} / Train Set Labels: {Ytrain.shape}')
Xval = dlls.iloc[val.indices, 2:]
Yval = dlls.iloc[val.indices, 1]
print(f'Validation Set Features: {Xval.shape} / Validation Set Labels: {Yval.shape}')
Xtest = dlls.iloc[test.indices, 2:]
Ytest = dlls.iloc[test.indices, 1]
print(f'Test Set Features: {Xtest.shape} / Test Set Labels: {Ytest.shape}')
class NeuralNetwork(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.model = nn.Sequential(
nn.Embedding(in_features, 3),
nn.Flatten(),
nn.Linear(3 * in_features, 64),
nn.ReLU(),
nn.Linear(64, out_features)
)
def forward(self, x):
return self.model(x)
model = NeuralNetwork(Xtrain.shape[1], 7)
optimizer = Adam(model.parameters())
loss = nn.CrossEntropyLoss()
for epoch in range(EPOCHS):
for batch_start in range(0, len(Xtrain), BATCH_SIZE):
Xbatch = torch.tensor(Xtrain[batch_start:batch_start + BATCH_SIZE].values)
Ybatch = torch.tensor(Ytrain[batch_start:batch_start + BATCH_SIZE].values)
model_output = model.forward(Xbatch)
output = loss(model_output, Ybatch)
optimizer.zero_grad()
output.backward()
optimizer.step()
print(f'Epoch: {epoch + 1} Loss: {output}')
with torch.set_grad_enabled(False):
val_preds = model.forward(torch.tensor(Xval.values))
class_predictions = np.argmax(F.softmax(val_preds, dim=1), axis=1)
acc = 100 * torch.sum(torch.eq(class_predictions, torch.tensor(Yval.values))) / len(Yval)
print(f'Validation Accuracy: {acc:.2f}%')
with torch.set_grad_enabled(False):
test_preds = model.forward(torch.tensor(Xtest.values))
class_predictions = np.argmax(F.softmax(test_preds, dim=1), axis=1)
acc = 100 * torch.sum(torch.eq(class_predictions, torch.tensor(Ytest.values))) / len(Ytest)
print(f'Test Set Accuracy: {acc:.2f}%')Performance
After training for 30 epochs, the model achieves roughly 60% accuracy on the test set. Not a bad start, but there’s certainly room for improvement.
Observations:
- The model achieves similar accuracy on the testing and validation sets. This suggests that the model isn’t overfitting.
- Increasing the depth of the network does not considerably change its performance. There is an underlying issue in the dataset. Here’s a visualization of the label (attack type) class distribution:
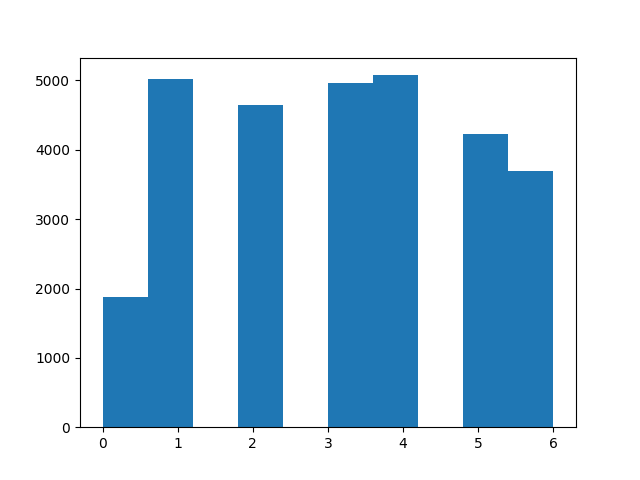
When I exclude rows in the dataset with a label of 0, the model validation/testing performance increases to 65%.
Improvements:
- Hyperparameter tuning. K-fold cross validation is the standard approach to set hyperparameter values like learning rate.
- Use more features. The Kaggle repository contains other dataset files with executable header data and specific API calls. Including more features would improve the model’s predictive power.
- Use a different model architecture. Traditional machine learning architectures, like K-Nearest-Neighbors (KNN), might be well-suited for this task: Intuitively, we would expect executables linking to similar DLLs to pose similar threats.